手机网站
手机网站
手机网站
手机网站
Spark SQL就是Spark生态系统中一个开源的数据仓库组件,可以认为是Hive在Spark的实现,用来存储历史数据,做OLAP、日志分析、数据挖掘、机器学习等等 本回答由提问者
为什么说Spark SQL远远超越了MPP SQL - 今
584x314 - 8KB - JPEG

为什么说Spark SQL远远超越了MPP SQL
600x312 - 259KB - PNG

Spark on Hive \/ 为什么spark-sql比hive慢?
901x323 - 16KB - PNG

为什么说Spark SQL远远超越了MPP SQL-其它
300x225 - 15KB - JPEG

为什么说Spark SQL远远超越了MPP SQL
584x314 - 11KB - JPEG

选择 Parquet for Spark SQL 的 5 大原因
980x458 - 28KB - JPEG
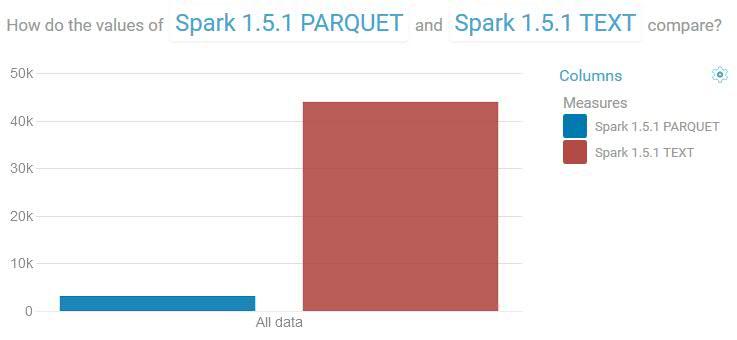
选择 Parquet for Spark SQL 的 5 大原因 - 51C
737x340 - 15KB - JPEG

选择 Parquet for Spark SQL 的 5 大原因
400x224 - 9KB - JPEG

选择 Parquet for Spark SQL 的 5 大原因
425x205 - 9KB - JPEG
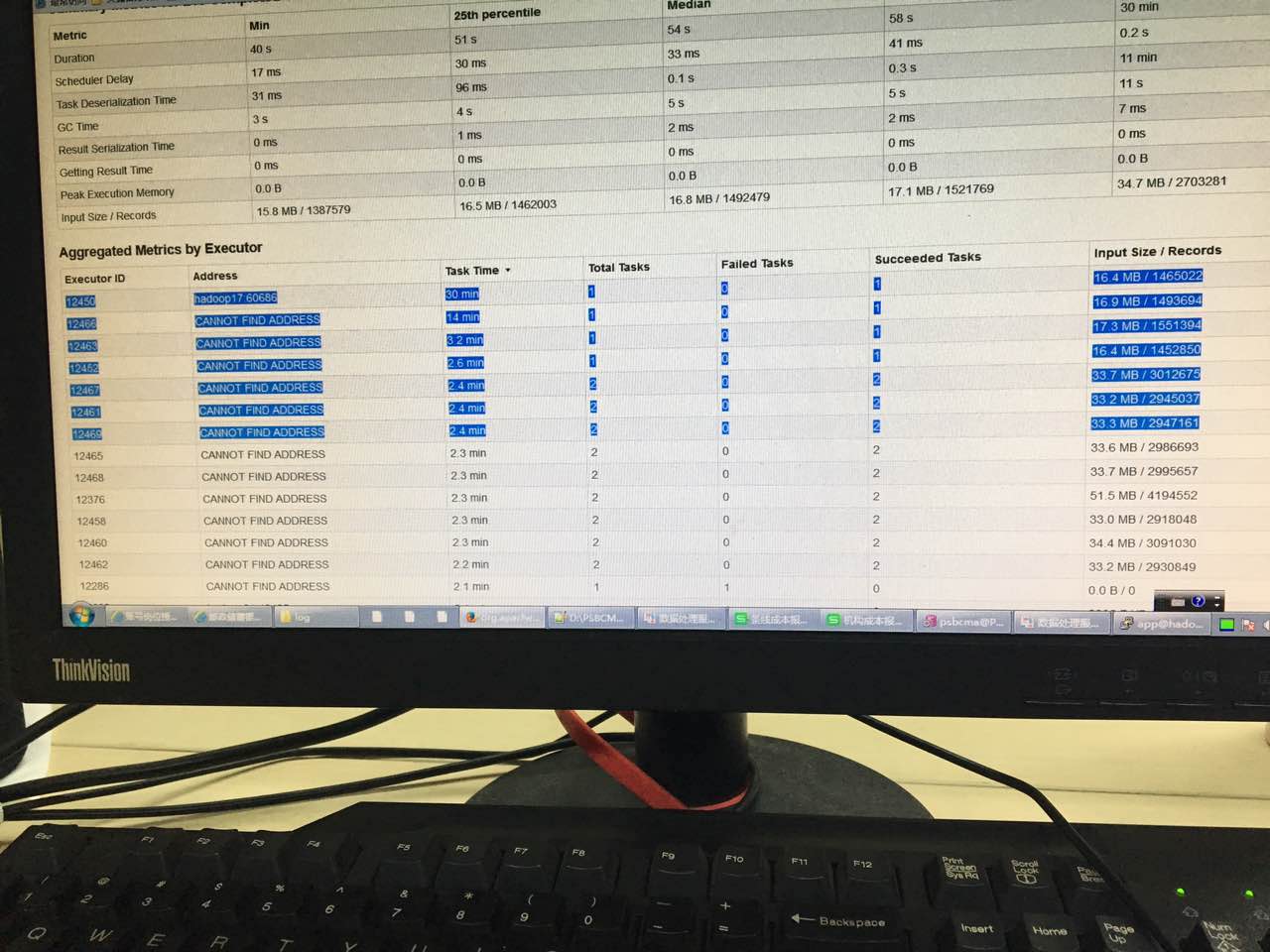
为什么spark sql有些任务特别慢?基本同样的in
1280x960 - 129KB - JPEG
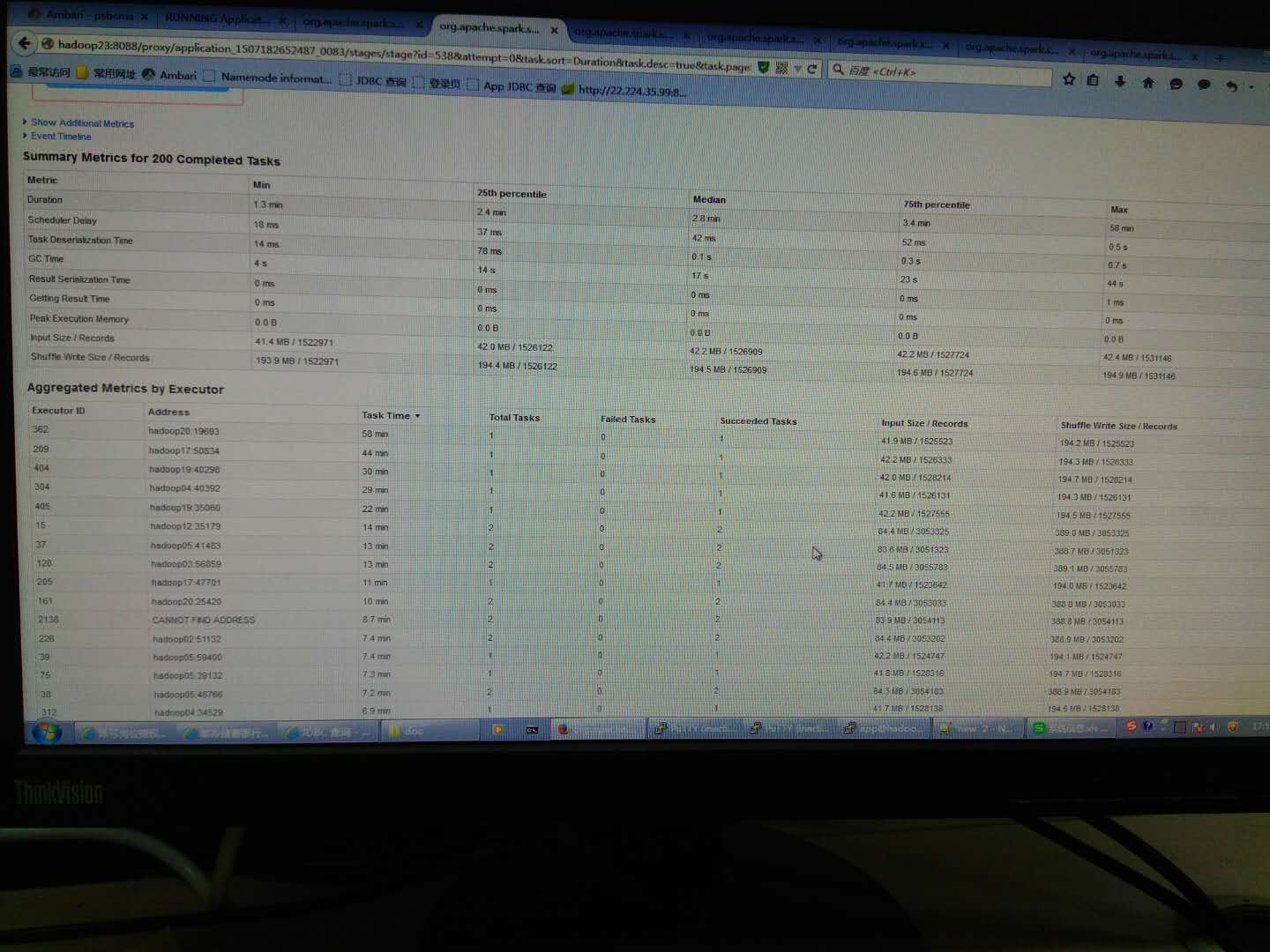
为什么spark sql有些任务特别慢?基本同样的in
1440x1080 - 111KB - JPEG

为什么spark sql有些任务特别慢?基本同样的in
1440x1080 - 118KB - JPEG

为什么spark sql有些任务特别慢?基本同样的in
1440x1080 - 108KB - JPEG

Spark on Hive \/ 为什么spark-sql比hive慢?
907x739 - 57KB - PNG

选择 Parquet for Spark SQL 的 5 大原因
980x455 - 22KB - JPEG