手机网站
手机网站
手机网站
手机网站
都是为了用类sql语句查询结果,一个从hdfs读文件,一个从hive库读数据从生产上有什么区别么?我的理解是在已经有hive应用的时候用spark hive而没有使用到hive得应用直接用s
Shark, Spark SQL, Hive on Spark, 及SQL 在Sp
690x465 - 34KB - JPEG

Flume+Spark+Hive+Spark SQL离线分析系统_
2352x1204 - 270KB - JPEG

大数据工程师学习路线_大数据工程师自学_大
640x363 - 50KB - PNG

Spark(Hive) SQL中UDF的使用(Python)_「电脑
792x531 - 94KB - PNG
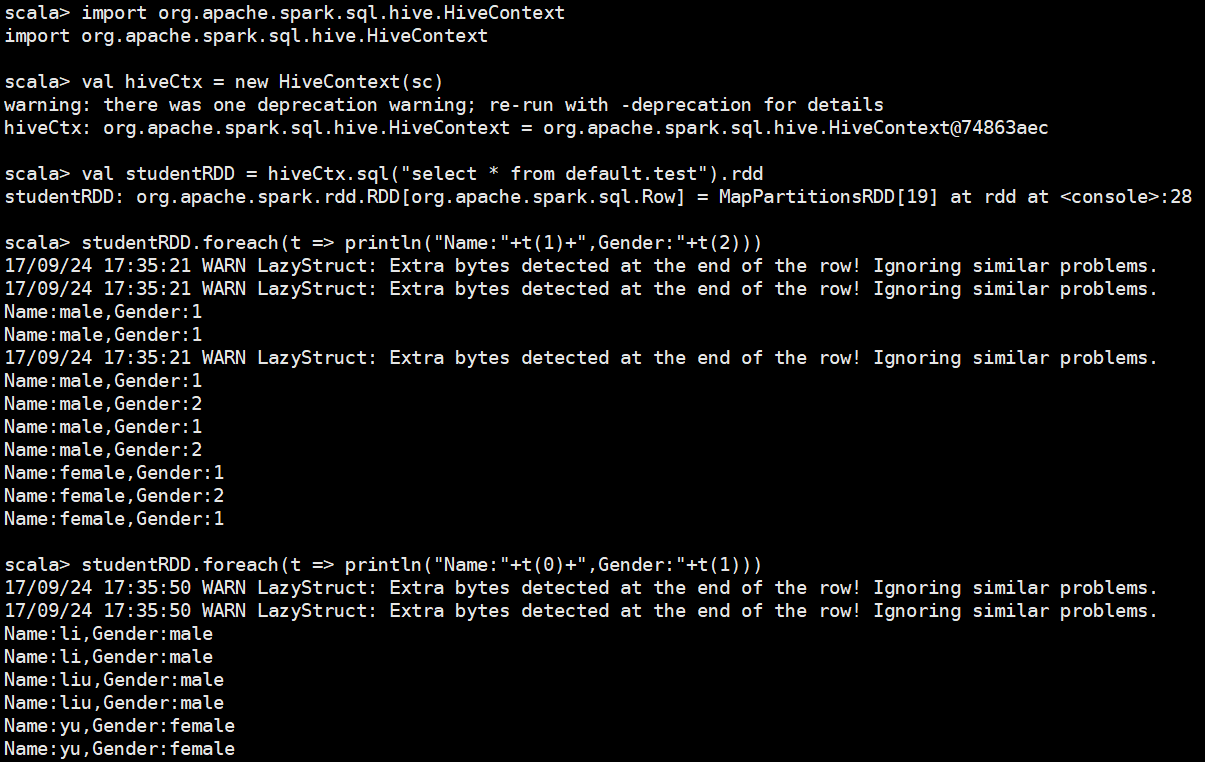
Spark-SQL连接Hive
1205x762 - 76KB - PNG

前世今生:Hive、Shark、spark SQL - 过雁
466x581 - 48KB - JPEG
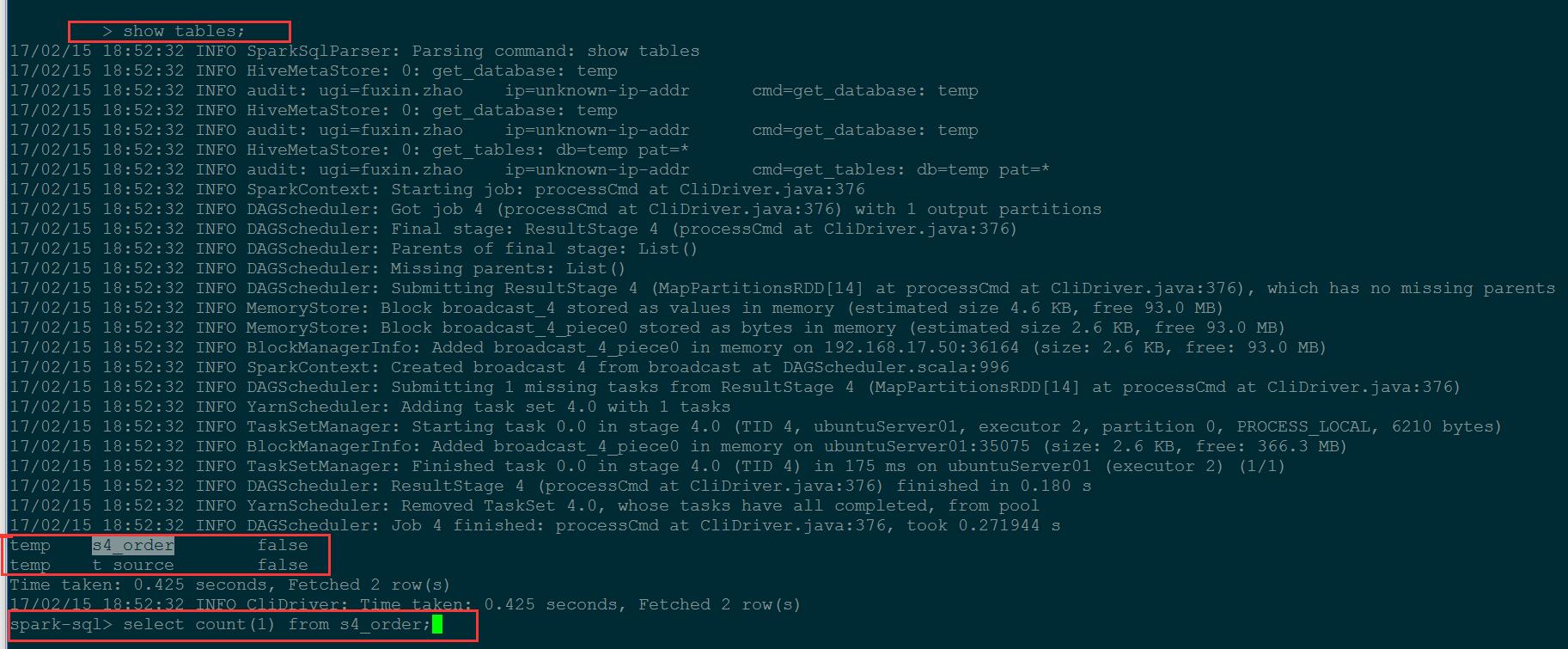
spark on yarn模式下配置spark-sql访问hive元数
1825x755 - 188KB - JPEG

Spark on Hive \/ 为什么spark-sql比hive慢?
901x323 - 16KB - PNG

Spark(Hive) SQL数据类型使用详解(Python)_P
700x597 - 173KB - PNG

Spark(Hive) SQL数据类型使用详解(Python)_P
700x606 - 168KB - PNG

Spark(Hive) SQL数据类型使用详解(Python)_P
700x460 - 131KB - PNG

Spark(Hive) SQL数据类型使用详解(Python)
1208x583 - 127KB - PNG

Spark(Hive) SQL数据类型使用详解(Python)
1023x575 - 130KB - PNG

Spark(Hive) SQL数据类型使用详解(Python)_P
700x393 - 126KB - PNG
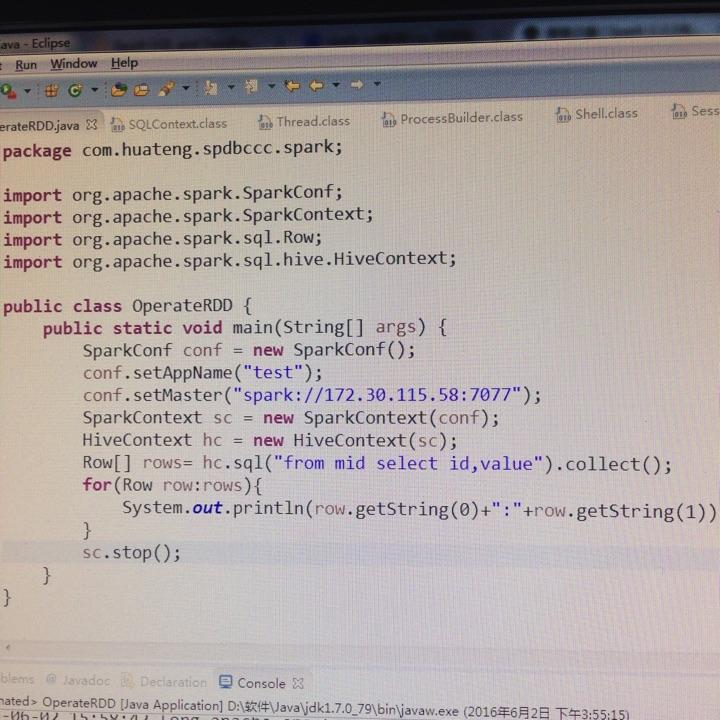
java spark sql 查询hive 表如何配置? - Spark
720x720 - 179KB - JPEG