手机网站
手机网站
手机网站
手机网站
Hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计

SparkSQL与Hive on Spark的比较 - 在路上的学
931x533 - 122KB - PNG
Shark, Spark SQL, Hive on Spark, 及SQL 在Sp
690x465 - 34KB - JPEG
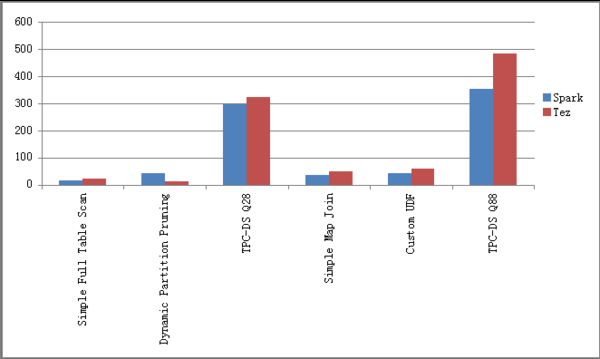
Intel李锐:Hive on Spark解析
600x359 - 28KB - JPEG

Hive on Spark & Tachyon解析
600x307 - 96KB - PNG

Intel李锐:Hive on Spark解析
580x345 - 16KB - PNG

Hive on Spark Field Guide
400x311 - 47KB - PNG

Hive on Spark预测性执行BUG一枚
550x321 - 51KB - JPEG

Flume+Spark+Hive+Spark SQL离线分析系统_
2352x1204 - 270KB - JPEG

大数据Spark:Hive序列化与反序列原理内幕和源
1277x577 - 361KB - PNG

大数据Spark:Hive序列化与反序列原理内幕和源
1285x504 - 221KB - PNG

Hive on Spark解析 中文PDF版
471x500 - 213KB - PNG
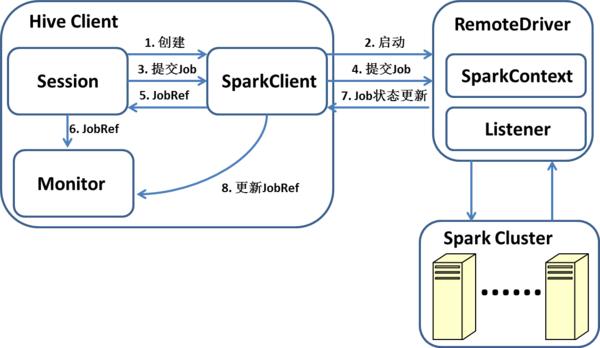
Intel李锐:Hive on Spark解析
600x348 - 47KB - JPEG

Spark on Hive \/ 为什么spark-sql比hive慢?
901x323 - 16KB - PNG
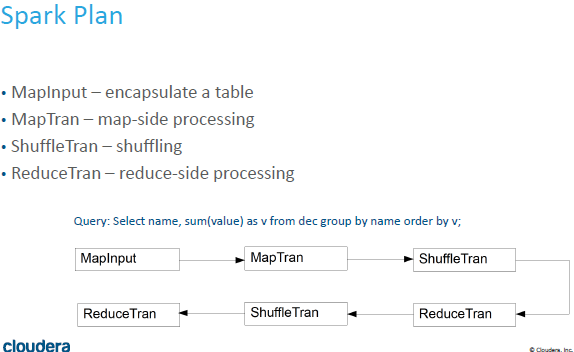
Hive on Spark & Tachyon解析-云计算-火龙果软
574x352 - 27KB - PNG

Hive on spark简介和安装
642x378 - 29KB - JPEG