手机网站
手机网站
手机网站
手机网站

背景
八卦协议也称为流行病协议。事实上,它有许多别名,如“流言算法”和“流行病传播算法”
的功能就像它的名字一样。这很容易理解。事实上,它的方式在我们的日常生活中也很常见,比如计算机病毒的传播、森林火灾、细胞增殖等等。
Gossip协议于1987年在ACM上发表的论文“复制数据库维护的流行算法”中首次提出它主要用于同步分布式数据库系统中每个副本节点的数据。这种情况的最大特点之一是网络的节点都是对等节点,这是非结构化网络。这与之前为结构化网络引入的分布式哈希表算法Kadmelia不同。
我们知道许多著名的P2P网络或区块链项目,如IPFS和以太网,都使用Kadmelia算法,而著名的比特币则使用Gossip协议来传播交易和阻止信息。
事实上,只要你仔细分析场景,以太网使用分布式哈希表算法是不太合理的,因为它使用节点来保存整个链的数据,不像IPFS把数据保存成碎片,所以以太网真正合适的协议应该是像比特币这样的八卦协议
在这里首先简要介绍了Gossip协议的实现过程:
Gossip过程由一个种子节点发起。当种子节点的状态需要更新到网络中的其他节点时,它会随机选择其周围的几个节点来传播消息,接收消息的节点会重复这个过程,直到网络中的所有节点最终接收到消息这个过程可能需要一些时间,因为它不能保证所有节点在某个时刻都会收到消息,但理论上所有节点最终都会收到消息,所以它是一个最终的一致性协议。在
下面,我们将通过一个具体的例子
来体验八卦传播的整个过程。为了说明这一点,我们首先要做一些前提设置:
流言是一个周期性的消息传播,限制周期为1秒
被感染的节点随机选择k个邻居节点来传播消息,这里扇出设置为3,一次最多传播到3个节点每次
传播消息时,它都会选择一个尚未发送的节点来传播
。接收消息的节点将不再将其传播到发送节点,例如A -> B,然后当B传播时,它将不再将其发送到A
这里总共有16个节点。节点1是最初被感染的节点。通过Gossip过程,最终所有节点都被感染:
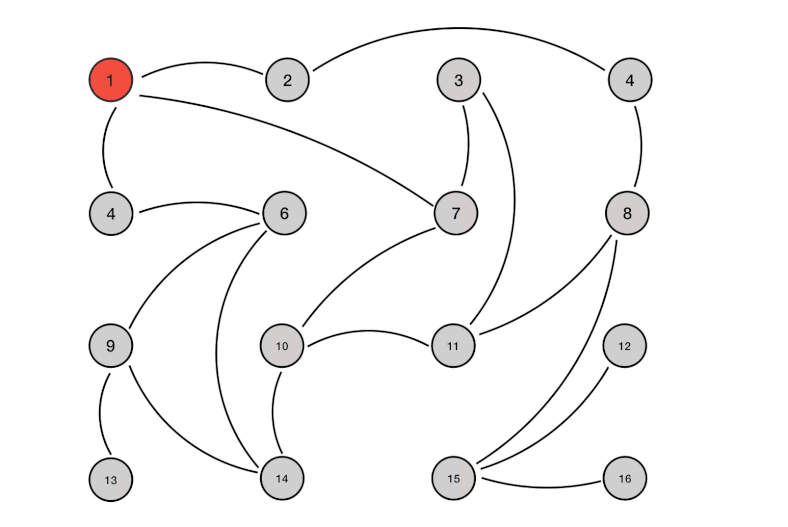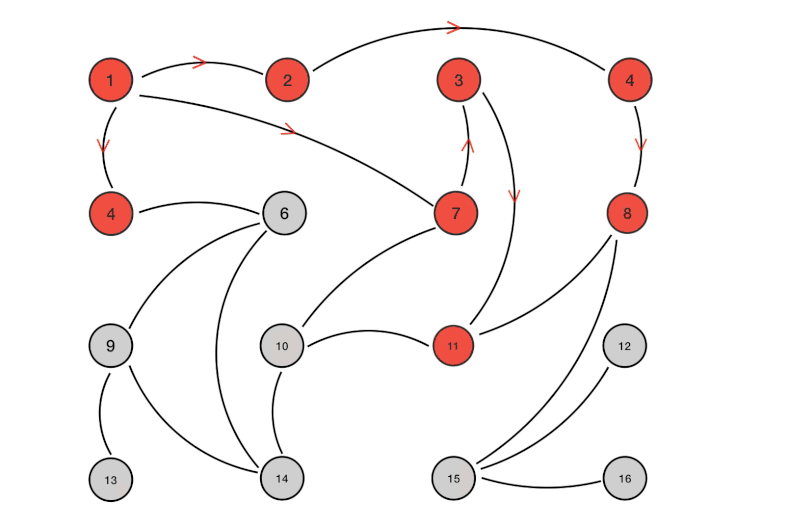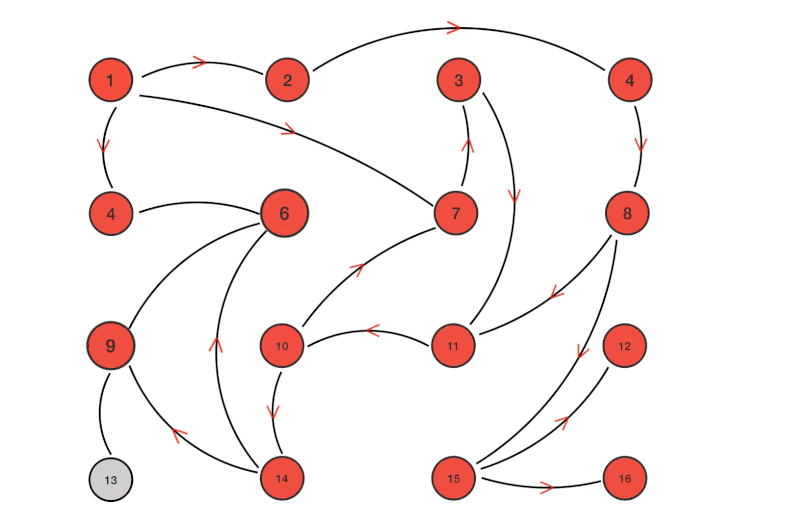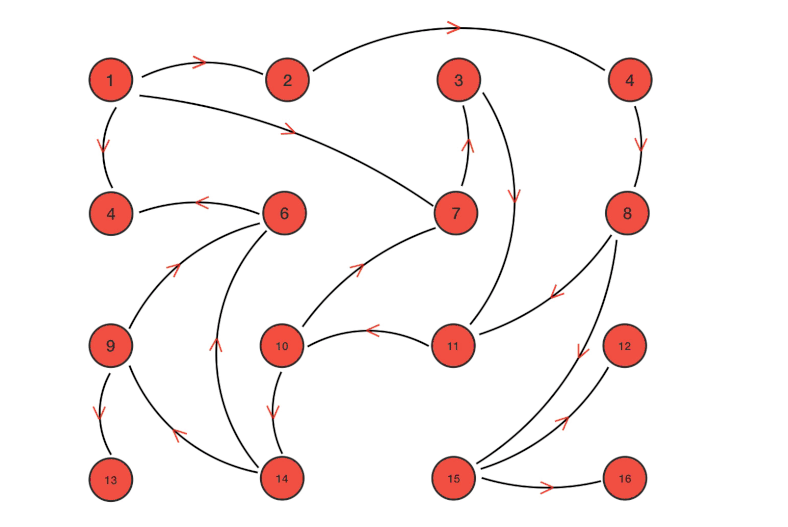
下面总结了
Gossip
1)可扩展性
网络可以允许任何节点的增加或减少。新添加节点的状态最终将与其他节点一致
2)容错停机和重启
网络中的任何节点都不会影响八卦消息的传播。Gossip协议具有分布式系统固有的容错特性
3)非集中式
Gossip协议不需要任何中心节点,所有节点都可以是对等的,任何节点都不需要知道整个网络的情况,只要网络连接,任何节点都可以将消息传播到整个网络。
4)一致性融合
Gossip协议中的消息将以10比10的指数速率在网络中快速传播,因此系统状态不一致可以在很短的时间内收敛到一致性。消息传播速度达到logN
5) Simple
Gossip协议过程极其简单,实现起来也不复杂
má rkjelasty在其著作《流言蜚语:

流言蜚语的缺陷》中对此进行了总结。八卦协议和其他协议一样,也有一些不可避免的缺陷。主要有两种:
1)消息延迟
。在Gossip协议中,节点只会随机地向少数几个节点发送消息,消息最终会通过多轮传播到达整个网络。因此,使用Gossip协议将导致不可避免的消息延迟它不适合实时性要求高的场景。
2)消息冗余
八卦协议规定,节点将随机选择周围的节点定期发送消息,接收消息的节点将重复此步骤。因此,消息不可避免地会重复发送到同一个节点,导致消息冗余,并增加接收消息的节点的处理压力。此外,因为它是定期发送的并且不反馈,所以即使节点接收到消息,它仍然会重复接收重复的消息,从而增加了消息的冗余
流言类型
流言有两种类型:
反熵:以固定概率散布所有数据散布谣言:仅散布新到达的数据
反熵是SI模型,节点只有两种状态,怀疑和感染,称为简单流行病
谣言传播是SIR模型,节点有三种状态,怀疑、感染和消除,称为复杂流行病学。
事实上,反熵是一个非常奇怪的名词。Jelasity解释了为什么它被定义为这样,因为熵指的是混乱的程度,并且在这种模式下,不同节点中的无序数据可以被消除,所以反熵是反无序的换句话说,它可以提高系统中节点之间的相似性。
在SI模式下,一个节点将与其他节点共享所有数据,以消除节点之间的任何数据不一致性,从而确保最终的完全一致性。
由于消息在SI模型下重复交换,消息的数量非常大而且没有限制,这对系统来说是一个巨大的开销。
,但是在谣言传播模式下,消息可以更频繁地发送,因为消息只包含最新的更新,而且大小更小此外,谣言消息将被标记为在某个时间点后被删除,并且不再被传播。因此,在SIR模型下,系统存在一定的不一致性概率。但是,
,因为在安全气囊系统模式下,消息在某个时间点之后不会传播,所以消息是有限的,并且系统开销很小在
Gossip
协议下,网络中的两个节点之间有三种通信模式:
推送:节点A将数据和相应的版本号推送到节点B,节点B更新数据拉取:在A中,节点A仅将数据密钥和版本推送到节点B,节点B将比A新的本地数据推送到节点A,节点A更新本地推取:与拉取类似,只多一步,节点A将比B新的本地数据推送到节点B,节点B更新本地数据。如果将两个节点的数据同步定义为一次一个周期,则推送需要通信一次,拉取需要两次,推/拉需要在一个周期内进行三次尽管消息数量有所增加,但就效果而言,推/拉是最好的。理论上,两个节点可以在一个周期内完全一致。直观地说,推/拉具有最快的收敛速度复杂性分析
对于一个有N个节点的网络,假设每个Gossip周期,新感染的节点可以感染至少一个新节点,然后Gossip协议退化为二叉树查找,在LogN周期后,整个网络被感染,时间开销为0由于每个节点每个周期至少发送一条消息,消息的复杂度为0请注意,这是Gossip理论上的最佳收敛速度,但在实际情况下,很难达到最佳收敛速度。
假设一个节点在第一个周期被感染的概率是π,在第一个周期被感染的概率是π+1,
1),那么拉模式:
2)推模式:
表明拉的收敛速度比推快,并且每个节点在每个周期被感染的概率是固定的p,因此Gossip算法基于p的平方收敛,也称为概率收敛,即
全文!