手机网站
手机网站
手机网站
手机网站
雷锋网络人工智能开发者出版社:2019年10月19日,第十八届中国计算语言学大会“中国法学研究杯”相似案例匹配评估研讨会在云南昆明圆满结束清华大学刘志远副教授、中国科学院软件研究所韩显培研究员、力法智能技术有限公司首席执行官涂存超博士出席会议。其中
,根据大会举办的中国法学研究杯类似案例的比赛评估大赛,支付宝的AlphaCourt团队夺冠,该团队致力于打造属于支付平台的“互联网法庭”。在这次竞赛中,他们充分利用数据挖掘、深度学习、神经网络等方法,实现了多模型集成、优化和可视化探索任务,如“多个法律文件的相似度计算和判断”。最后,他们以71.88的优异成绩赢得了冠军。在
199的比赛中,我们也可以看到京东、华宇、同济等强敌,但是阿尔法阁队在711参赛队伍中,在哪些技术和方法上略胜一筹呢?雷锋的人工智能开发者有幸采访了冠军团队,并对他们的冠军计划进行了如下分析。也许我们可以一起找到答案。
刘致远副教授向一等奖团队介绍了
竞赛简介本次法律研究杯司法人工智能挑战赛主要围绕“相似案例的匹配与评价”这一主题。竞争任务涉及对相似案例的理解和判断,其中最具代表性的是民间借贷的相似案例。如果人工智能技术能够对大量的案例进行分类和判断,那么重复劳动成本和其他实际问题将会大大减少。
因此,这项任务的第一步是计算和判断许多法律文件的相似性。然后提供每个文档的标题和事实描述,并从两个候选集合文档中找到一个与查询文档更相似的文档。其中,类似案例的匹配数据仅限于私人贷款等文件。

民间借贷相似案例匹配实例
在数据集方面,本次任务使用的数据集是中国司法文献网发布的法律文件,每组数据由三个法律文件组成对于每份法律文件,只提供事实的描述;对于每一条数据,用(a,b,c)来表示这组数据;对于训练数据,确保文档数据A和B之间的相似性大于文档数据A和c之间的相似性
在此类竞赛问题的背景下,各参赛队开始用自己的技术方法不断提高人工智能判断的准确性
阿尔法法院团队冠军团队阿尔法法院来自支付宝安全实验室。参与成员包括:
卡格莱大师包
KDD 2019冠军易灿
神医刘星
杜克大学叶恒大师
爱丁堡大学小通

该团队的日常工作是分析和处理用户通过人工智能算法反馈的欺诈等风险信息,以便更好地防控和保护用户账户这也是他们团队名称“阿尔法法院——智能法院”的由来,因为在他们的业务范围内,每个人的职能都与法院的职能相同,旨在分配正义和消除不公正。
因此,我们可以发现团队在这场竞争中有两大优势:
1是业务涉及到丰富的文本并存放了许多与文本相关的算法;
2是团队构建的欺诈案例知识地图,也帮助他们很好地构建了业务抽象元素的框架,并与文本模型相结合,丰富了模型的学习维度。
虽然团队拥有丰富且熟悉的经验和技能,但除了法律案件中的各种困难之外,他们还有其他困难和挑战需要克服,如文字冗长、案件高度复杂、灵活多样、案例分析价值众多等。
挑战1:数据构建和句子相似性确定在比赛中,团队首先面临的大挑战是竞赛问题的数据构建形式较少队长说,虽然他们在日常工作中对文本分类问题很熟悉,但比赛的主题是三个文本之间的比较,所以需要一些转换。
因此,起初他们做了一个简单的假设,把竞争问题变成了一个绝对相似的问题。假设文档数据A和文档数据B之间的对应关系是绝对相似的,同时文档数据A和文档数据C之间的对应关系是绝对不同的,也就是说,原始三元组数据是否被分成两个或两个文档数据是绝对相似的,那么二分法模型可以用来解决这样的问题。
,但事实上,当数据在第二阶段被检查时,团队发现了一些与之前绝对相似性假设的问题。虽然数据(A,B,C)确保文档数据A和B之间的相似性大于A和C之间的相似性,但情况(A,D,B)将出现在其他数据中。当这两个三元组样本同时被分成两对具有相似比较的数据时,将会发现产生数据的标签有冲突。
因此,该团队在第一阶段使用两类模型的思想重新考虑了三胞胎的相对相似性。最后,他们采用三重损失损失函数的秩模型来解决三重损失的相对相似性问题,并从两个文本之间的相似距离来评价两个文本之间的相似性。
两个模型的思维框架如下图所示
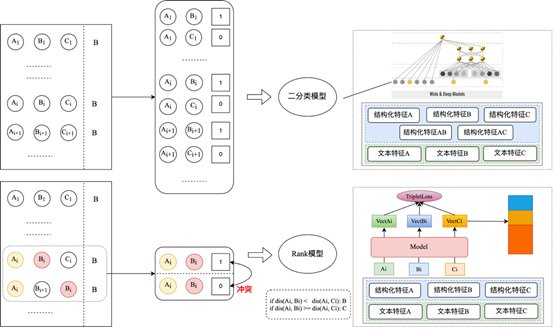
解决相对相似问题的模型
挑战2:文本形式差异队长告诉我们,他们每天都在处理用户自由填写的文本,信息稀疏,没有固定的结构,而竞争问题是半结构化的法律文件,因此有必要构建与竞争问题的诉讼原因相关的抽象业务特征
因此,主要参考合同法、担保法、婚姻法及相关司法解释,归纳出原告/被告属性、担保类型(一般和连带)、计息方法、约定贷款利率、约定逾期利率、抵押物、约定贷款证明等七个特征最后,根据可行性和数据表现,选择了原告和被告、担保和利益的特征。
原告和被告的特征包括原告是否属于公司、原告人数、被告是否属于公司和被告人数;
保证功能包括单据是否包含保证人、保证人的数量、单据是否包含担保物以及担保物的数量;
利息特征包括单据是否包含利息和利息金额的换算其他业务特征包括文件中被告之间是否存在婚姻关系以及被告死亡;
具体提取的结构特征如下图所示:
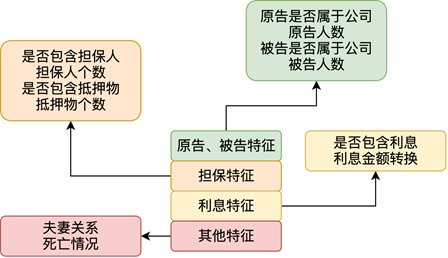
具体提取的结构特征与建模关系不大,但结果证明这些业务抽象特征确实带来了很好的收益。同时,从竞争计划来看,这也是其他竞争对手没有特别注意的细节。对于这一点的处理,我不禁感慨:这的确是“细节决定成败”的最有力的陈述。
挑战3:模型优化本次比赛有711个团队,共有1003名参与者激烈的竞争是不可避免的,在竞争的过程中,前几名之间的得分差距基本上在5分以内,相互追逐,很有可能发生激烈的争斗。因此,阿尔法法院团队也在不断优化模型,主要使用两个技巧。
模型融合
第一个技巧是模型融合;该团队尝试使用伯特模型作为基线模型,然后进一步优化了伯特模型优化方案包括:
提取伯特模型内部的网络层输出,通过提取最后两三层中每一层的第一状态输出向量,并尝试与原伯特模型的输出进行拼接,可以得到更全面的特征向量,如下图(2)(3);
将正则表达式提取的业务抽象特征和TF-IDF提取的文本数据词频统计等结构特征结合起来,与Bert模型的输出进行拼接,结合结构特征的特征合理性得到更优化的特征向量,如下图(4)所示。除了输出特征向量,
Bert模型还提供了模型的状态信息,可以连接更深层次的网络模型,如双LSTM和双GRU网络模型文本的高维特征可以通过更深层次的网络模型来提取。双GRU网络层的输出特性和隐藏层状态的特性是通过汇集和提取隐藏层状态等操作来聚合的,如下图(5)所示
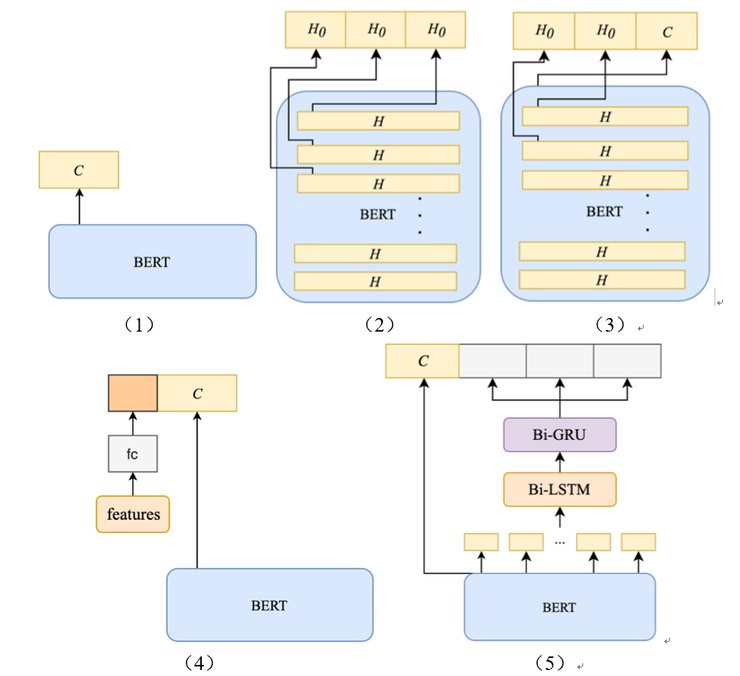
五种网络模型
通过以上五种网络模型,多模型离线多模型融合可以进一步提高相似匹配的准确性,如下图所示
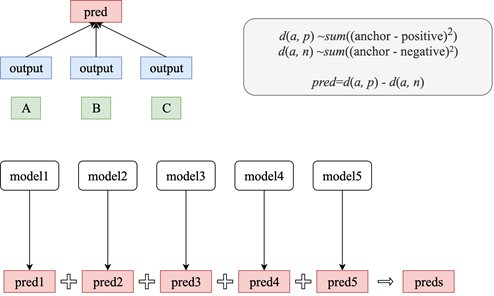
多模型离线多模型融合
三重损耗过拟合
另一个技巧是三重损耗过拟合的解决方案;因为样本是以三元组的形式输入的,所以默认查询文档数据A和文档数据B之间的相似性大于查询文档数据A和文档数据C之间的相似性此时,在训练过程中可能会出现一种极端情况,即模型结果没有脑输出b,并且会出现过度拟合问题
AlphaCourt团队在这里使用的解决方案是部分修改文本数据B和文本数据C的顺序,使一半的数据变成(A,C,B)形式的三元组数据,也就是说,B和C的标签可以同时存在。具体操作流程如下
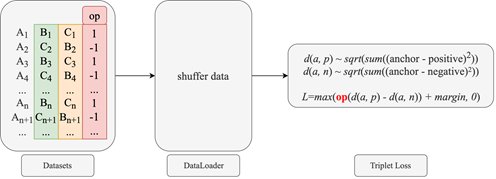
三重损失过拟合方案的解决方案
当构建训练和验证数据集时,值为1的变量op被附加到奇数编号的三重样本用值为-1的变量op交换偶数三联体样本的文档数据b和文档数据c默认情况下,构建的数据集将通过数据加载器中断,因此不会学习数据标记规则。当
最终得知本征向量由三重损失计算时,只要变量op附加到计算过程中,并调整两者之间欧氏距离的正负结果,就可以保证三重损失的计算结果是正确的。
以上是冠军计划最核心的部分的诠释。此外,详细介绍了编码层、特征交互层、数据增强、模型预训练等细节。请参考-
< p > github开放源代码:
https://github.com/guidopoul/cail2019
从这场竞争中,我们可以看到,人工智能技术,曾经局限于互联网领域,现在开始逐渐在金融、法律甚至矿工领域发光,发挥着实际作用。此外,这并不是唯一一次举行人工智能法律竞赛的会议。仍然有很多这样的比赛。例如:
< p >法律助理人工智能(AILA)
详细信息:https://sites.google.com/view/fire-2019-aila/
法律信息抽取/蕴涵竞赛
详细信息:https://sites.ualberta.ca/~rabelo/COLIEE2019/
这些竞赛都是通过人工智能技术解决法律案件中的大量数据、复杂数据、检索错误等实际问题。我们还通过竞赛获得了许多实用和优秀的算法,帮助我们的生活变得更加方便和快乐。在
之前,我们很容易在互联网、大数据和其他领域看到人工智能。现在,人工智能已经被注入到法律、金融、医疗、交通、教育、零售和娱乐等各个行业。这也可能证明我们离国家人工智能更近了一步

雷锋网络人工智能开发者