手机网站
手机网站
手机网站
手机网站
# coding:utf-8 import re import urllib.request def juubao(n, pprice): 实现从juubao网站爬取前n页,折扣大于pprice的商品链接 :param n:网站的前n页 :param pprice:最低优惠券价格
Scrapy爬虫实战-东方购物网站的爬取 - 今日头
550x388 - 20KB - JPEG
Scrapy爬虫实战-东方购物网站的爬取 - 今日头
555x253 - 9KB - JPEG

网页网站web信息数据定制采集收集爬取爬虫服
200x200 - 8KB - JPEG
东方购物Scrapy爬虫第二弹--分类页面+商品详
523x577 - 50KB - JPEG
爬取任何垂直网站的信息,10W一下数据1天内完
915x725 - 447KB - PNG

网页数据爬取\/采集\/数据抓取\/爬虫\/新闻\/微博\/微
200x200 - 15KB - JPEG

python制作爬虫爬取京东商品评论教程-Ruby-程
530x385 - 10KB - PNG

搜索引擎蜘蛛每天怎么样爬取网的?搜索引擎蜘
800x452 - 55KB - JPEG

淘宝爬取某人的所有购物订单 - 北风之神0509
1119x872 - 150KB - PNG

爬虫凶猛:爬支付宝、爬微信、窃取现金贷放贷
408x695 - 66KB - JPEG

爬虫泛滥:爬现金贷窃取数据,支付宝和微信也
390x632 - 197KB - PNG

爬虫泛滥:爬现金贷窃取数据,支付宝和微信也
408x695 - 46KB - JPEG

爬虫泛滥:爬现金贷窃取数据,支付宝和微信也
408x695 - 99KB - JPEG

python爬取淘宝商品信息并加入购物车
148x143 - 7KB - JPEG
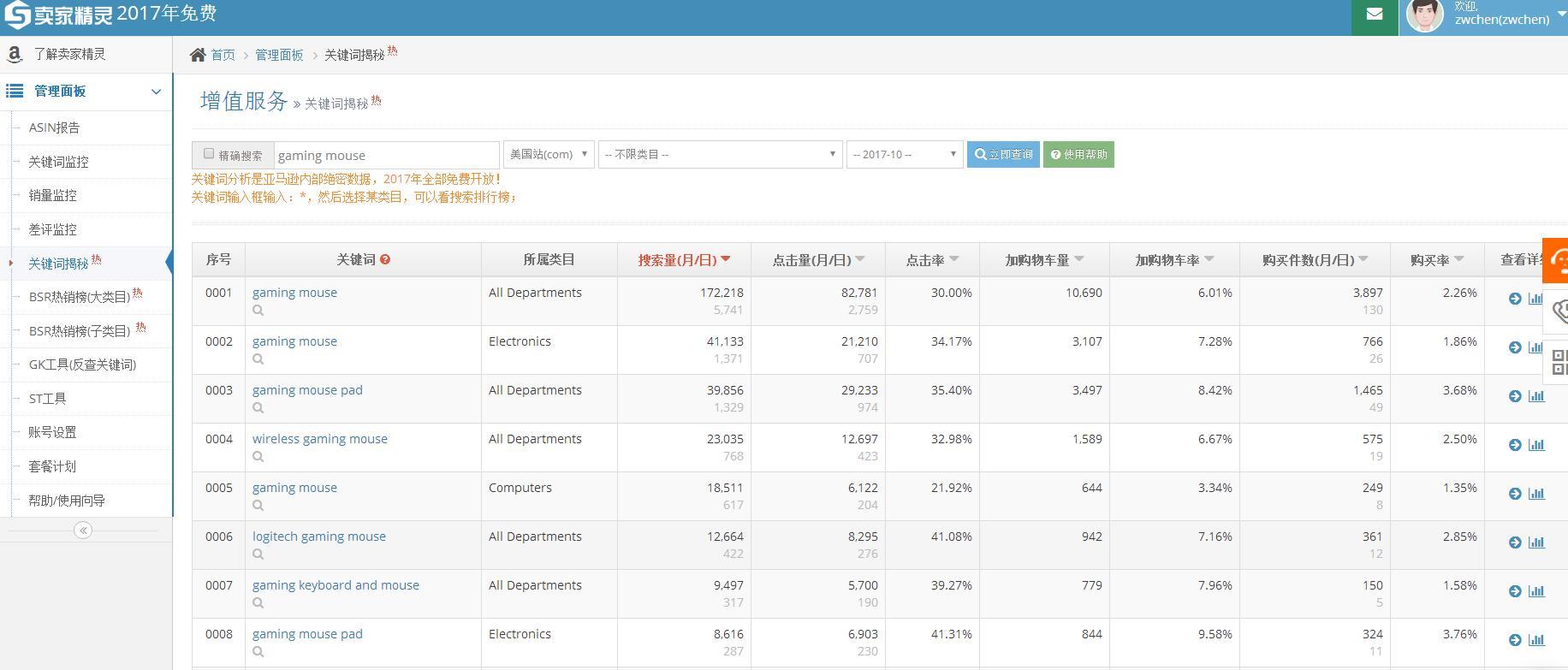
卖家精灵和Merchant Words对比哪个更好用?
1832x783 - 125KB - JPEG