手机网站
手机网站
手机网站
手机网站
这里主要对爬虫以及抓取系统进行一个简单的概述。一、网络爬虫的基本结构及工作流程一个通用的网络爬虫的框架如图所示:网络爬虫的基本工作流程如下: 1.首先选取一部分

网络爬虫简单原理_「电脑玩物」中文网我们只
921x603 - 103KB - PNG

浅析搜索引擎蜘蛛抓取网页规则
500x287 - 51KB - JPEG

搜索引擎(网络爬虫篇)
921x603 - 108KB - PNG

python网络爬虫(一):网络爬虫科普与URL含义
597x491 - 191KB - PNG
![科学网-[转载]网络爬虫基本原理](http://image.sciencenet.cn/album/201503/31/192858jsi6zwescrepcvix.jpg)
科学网-[转载]网络爬虫基本原理
867x702 - 49KB - JPEG

爬虫工作原理大揭秘
557x473 - 48KB - JPEG
爬虫技术是什么,真的只能用Python写吗? - 今日
633x377 - 24KB - JPEG

python网络爬虫-爬取网页的通用代码框架及HT
640x335 - 23KB - JPEG

python网络爬虫-爬取网页的通用代码框架及HT
640x335 - 25KB - JPEG

python网络爬虫-爬取网页的通用代码框架及HT
640x335 - 28KB - JPEG

python网络爬虫-爬取网页的通用代码框架及HT
640x335 - 73KB - JPEG

python网络爬虫-爬取网页的通用代码框架及HT
640x335 - 69KB - JPEG

基于HttpClient4.0的网络爬虫基本框架(Java实现
808x606 - 114KB - JPEG
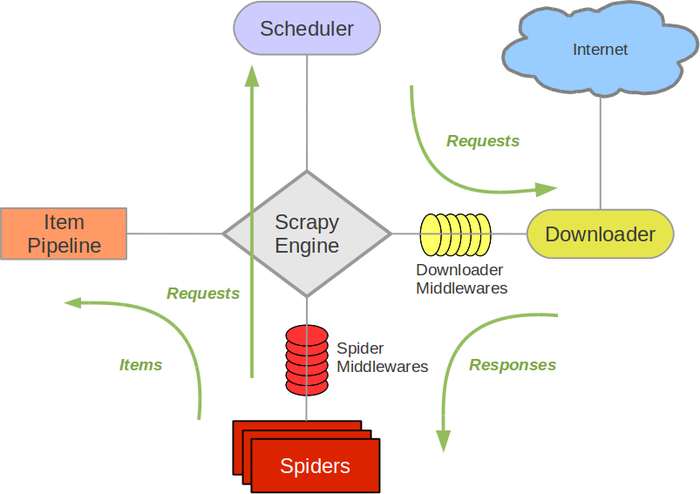
Scrapy的架构初探 - 一起学习python网络爬虫
700x494 - 90KB - PNG

网络爬虫基本原理(一) - 51CTO.COM
651x432 - 155KB - PNG