手机网站
手机网站
手机网站
手机网站
决定了map任务的个数比mapred,InputFormat在默认情况下会根据hadoop集群的DFS块大小进行分片,当用户的map数量较小或者比本身自动分割的值还小时可以使用一个相对

Flume+Spark+Hive+Spark SQL离线分析系统_
2352x1204 - 270KB - JPEG
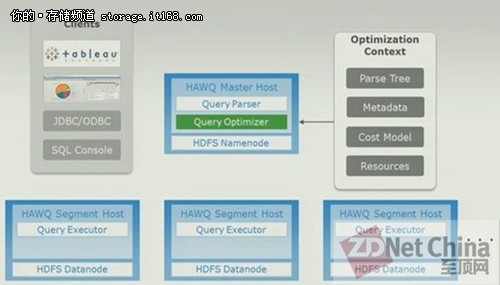
EMC讲解Hawq SQL:左手Hive右手Impala
500x285 - 38KB - JPEG
Shark, Spark SQL, Hive on Spark, 及SQL 在Sp
690x465 - 34KB - JPEG

EMC讲解Hawq SQL:左手Hive右手Impala
500x285 - 38KB - JPEG

Hive SQL 编译过程详解 - OPEN 开发经验库
1083x439 - 191KB - PNG

Hive SQL 监控系统 - Hive Falcon - OPEN 开发
2376x1146 - 366KB - PNG

Hive SQL运行状态监控(HiveSQLMonitor) - 综合
742x827 - 58KB - PNG

Hive SQL运行状态监控(HiveSQLMonitor) - 综合
664x348 - 18KB - PNG

Hive SQL 监控系统 - Hive Falcon - OPEN 开发
2374x1382 - 275KB - PNG

大数据工程师学习路线_大数据工程师自学_大
640x363 - 50KB - PNG

Spark(Hive) SQL中UDF的使用(Python)_「电脑
792x531 - 94KB - PNG
Hive SQL汇总 - 一无所有 QQ:934033381 - 51C
1024x768 - 141KB - JPEG

【转】Hive SQL的编译过程
907x420 - 60KB - PNG

Hive SQL运行状态监控(HiveSQLMonitor) - 综合
310x301 - 11KB - PNG

Hive SQL运行状态监控(HiveSQLMonitor)
989x731 - 76KB - PNG