手机网站
手机网站
手机网站
手机网站
参考资料:极客学院: Python单线程爬虫代码:2.Single-thread-crawler.ipynb本文内容: Requests.get爬取多个页码的网页例:爬取极客学院课程列表爬虫步骤打开目标网页,先查看网
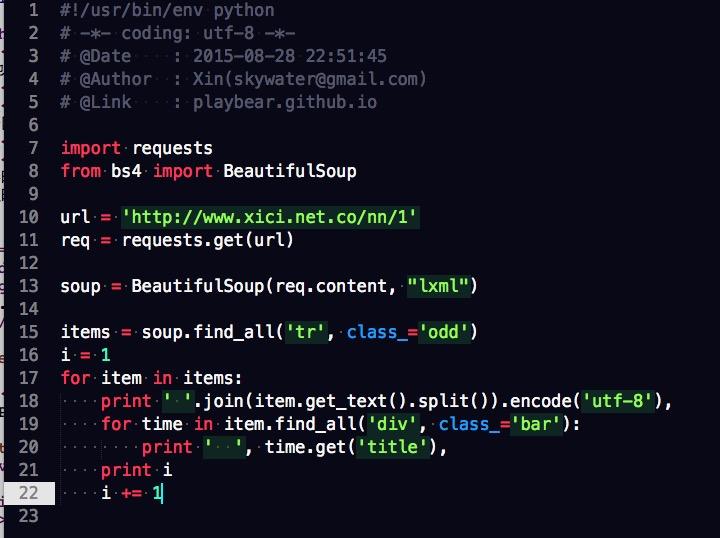
Python 爬虫爬取页面的信息? - 洛克的回答
720x538 - 86KB - JPEG
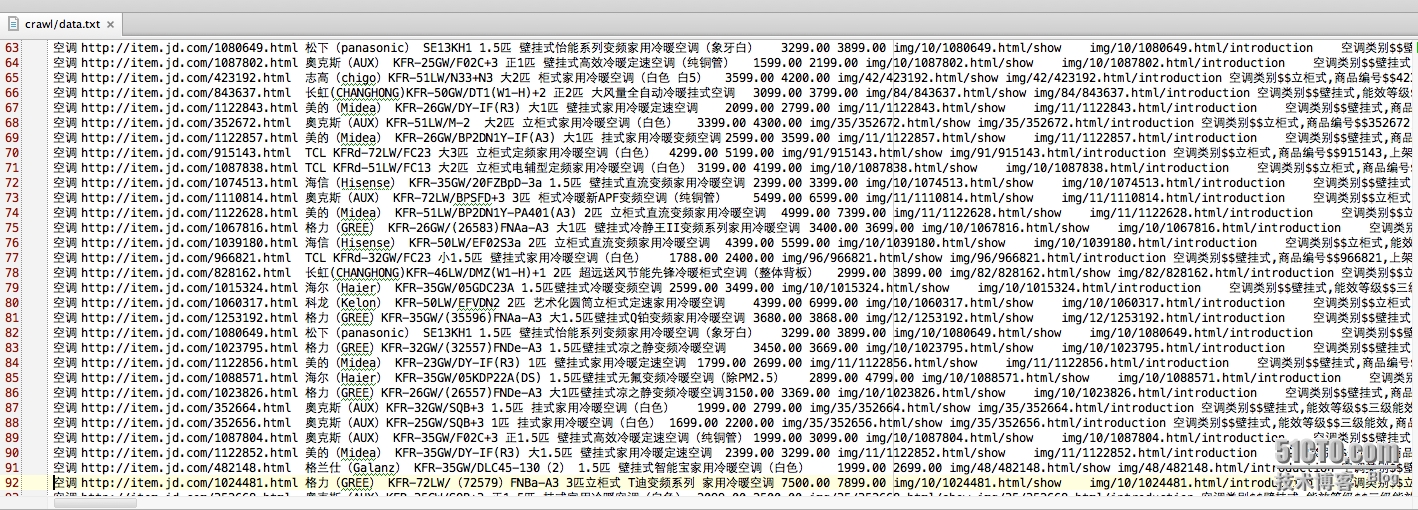
python爬虫实战,多线程爬取京东jd html页面:无
1418x510 - 1148KB - JPEG

python爬虫,爬取百度百科python词条页面数据,
1366x736 - 153KB - PNG

python爬虫实战,多线程爬取京东jd html页面:无
700x380 - 118KB - JPEG

python爬虫实战,多线程爬取京东jd html页面-Py
700x252 - 172KB - JPEG

python爬虫实战,多线程爬取京东jd html页面:无
700x293 - 81KB - JPEG

python爬虫实战,多线程爬取京东jd html页面-Py
504x323 - 124KB - JPEG

python爬虫实战,多线程爬取京东jd html页面:无
550x230 - 17KB - JPEG

python爬虫实战,多线程爬取京东jd html页面:无
1090x592 - 332KB - JPEG

爬虫修炼之道
300x240 - 35KB - PNG

python爬虫实战,多线程爬取京东jd html页面 - P
700x252 - 63KB - JPEG

python爬虫实战,多线程爬取京东jd html页面 - P
358x519 - 217KB - JPEG

爬虫之Python静态页面爬取 - Widsom的博客 -
853x1453 - 120KB - PNG

Python3.X 爬虫实战(动态页面爬取解析)_Pytho
550x235 - 67KB - PNG
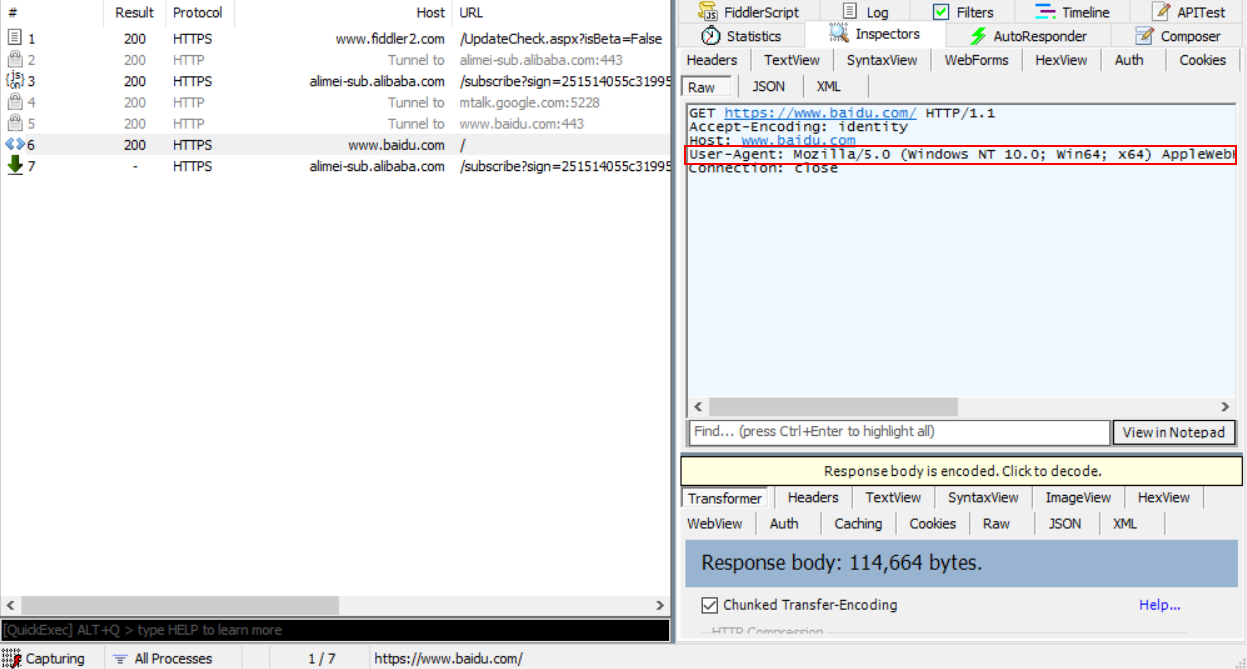
爬虫之Python静态页面爬取 - Widsom的博客 -
1247x669 - 190KB - PNG